-
판다스가 너무 느리다면? Polars!학습/Python 2024. 5. 7. 00:56

대용량 데이터에서는 사용 불가능한 Pandas
분석가가 과제를 수행하면서 이미 집계된 데이터를 분석하는 경우가 많지만
경우에 따라서는 전혀 가공되지 않은 날것의 데이터를 가공하는 경우도 종종 발생한다.
요즘은 워낙 로컬 머신의 성능도 좋아지기도 했고특히 개발 환경이 클라우드에 세팅되어 있는 분석가라면 사용중인 머신의 성능을 업그레이드 하는 방식을 통해
어느정도 수준의 큰 데이터는 쉽게 처리가 가능하다.
그러나 수 백 억 row 이상되는 정말 대용량의 데이터를 분석하는 경우에는위의 방법을 적용해봐도 한계를 마주치게 되고 pandas의 read_* 함수 따위는 리소스 부족으로 MemoryError가 발생하며 실행 자체가 되지 않는다... 메모리에 이 데이터를 올릴 수 없다는 얘기..
겨우겨우 데이터를 메모리에 올렸더라도 작업속도가 너무 느려서 분석의 의욕을 잃게 된다.. (팬더는 원래 느린 동물인가..?)
심지어 툭하면 세션 종료 메세지가 뜨면서 코드를 처음부터 다시 돌려야 하는 속터지는 상황도 종종 발생하게 된다.즉, pandas 는 데이터 크기가 너무 큰 경우에는 사용하기 어렵고 비효율적이다.
그래서 요즘 내가 Python에서 대용량 데이터를 처리할 때 사용하는 매우 쉽고/간편하고/빠른 방법인 Polars 를 제안하면서혹시 어디선가 거대한 데이터로 인해 고통스러워하는 분석가들에게 조금의 도움이 될 수 있길 바란다.
Polars 장점?
Polars의 대표적인 장점은 다음과 같다.
- Rust 기반으로 작성되어 병렬적 코드구현에 우수
- 멀티 코어로 동작하여 빠른 처리 속도
- Lazy execution 으로 연산 최적화 가능
나같이 개발 지식이 많지 않은 분석가라면 위에 적힌 장점이 그닥 와닿지 않을 수 있는데,
쉽게 말하자면 “Pandas 에서는 메모리 부족으로 실행도 되지 않는 작업이 Polars에서는 상당히 빠르게 처리 가능하다.”
라고 이해하면 될 것 같다.
특히 싱글코어로 연산처리하는 Pandas에 비해머신의 모든 가용 코어를 활용하여 연산처리하는 Polars는
처리 속도면에서 압도적일 것이라는 것을 쉽게 추측할 수 있다.
Lazy Execution?
내가 생각하는 Polars의 핵심은 바로 Lazy Execution 이 가능하다는 점이다.
Polars 사용법 때문에 국내 블로그를 몇 군데 검색하면서 찾아봤는데 이 점을 언급한 곳이 거의 없어서
본 포스팅에서 살짝 언급해보겠다.
Lazy Execution은 코드 실행시 즉시 연산을 수행하는 것이 아니라
코드의 실행 계획을 최적화하여 optimized plan만 저장하고 있다가.
추후 .collect()함수와 같은 실제 실행 명령이 주어질 때 plan에 대한 결과물을 출력하는 방식이다.
예시를 통해 Lazy Execution을 알아보자.
아래의 작업을 순서대로 수행하는 코드를 작성했다고 가정한다.
작업1) Join : tableA와 tableB 를 x3으로 조인하여 tableC에 할당
작업2) Filtering : tableC에서 (x1==2)인 row를 필터링Lazy Execution 예시(1)
우선 .collect() 함수를 사용하여 즉시 실행하면서 각 작업의 결과를 단계별로 확인해보자.
# 테이블 정의
# tableA, tableB 정의 tableA = pl.LazyFrame([[1,'a','가'],[2,'b','나'],[3,'c','다']], ['x1','x2','x3']) tableB = pl.LazyFrame([['나','x','apple'],['다','z','banana']], ['x3','x4','x5']) # tableA, tableB 출력 tableA.collect() tableB.collect()
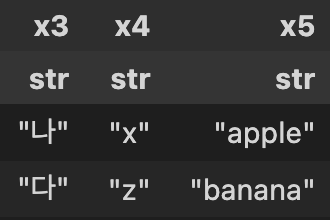
tableA(좌측), tableB(우측) # 작업1. Join
# 작업1. Join tableC = tableA.join(tableB, on='x3') tableC.collect()
tableC # 작업2. Filtering
# 작업2. Filtering tableC.filter(pl.col('x1')==2).collect()
tableC의 필터링 결과 만약 x1컬럼이 2인 데이터만 필요하다는 조건을 처음부터 알았다면
tableA에서 x1컬럼이 2인 조건의 데이터만 우선 가져온 후 tableB와 조인하는 것이 효율적인 방법일 것이다 (=optimized plan).
Lazy Execution 예시(2)
이제 각각의 작업을 하나씩 실행(collect) 하지 않고
result 변수에 한번에 정의한 후 최적화된 plan의 그래프와 최적화 되지 않은 plan의 그래프를 비교해보자.
# tableA, tableB 정의 tableA = pl.LazyFrame([[1,'a','가'],[2,'b','나'],[3,'c','다']], ['x1','x2','x3']) tableB = pl.LazyFrame([['나','x','apple'],['다','z','banana']], ['x3','x4','x5']) # 작업1. Join tableC = tableA.join(tableB, on='x3') # 작업2. Filtering result = tableC.filter(pl.col('x1')==2) # 결과 출력 result.collect() # non-optimized plan result.show_graph(optimized=False) # optimized plan result.show_graph()

non-optimized plan(좌), optimized plan(우) 좌측의 non-optimized plan의 그래프는 Lazy Execution 예시(1) 처럼 각 작업을 순서대로 수행하는 그래프이고,
우측의 그래프는 tableA를 우선 필터링 한 이후에 조인하는 등 optimized plan 그래프를 확인할 수 있다.
polars에서는 기본적으로 optimized plan을 채택하여 작업을 수행한다.
결론.
예시가 너무 간단해서 non-optimized와 optimized간 성능 차이가 크지 않지만,
데이터의 양이 많을수록 optimized plan으로 인한 연산 성능이 기하급수적으로 개선된다.
또한 불필요한 데이터를 메모리에 올리지 않기 때문에 메모리를 효율적으로 활용할 수 있다는 장점이 있다.이것이 pandas 대신 polars를 사용하는 궁극적인 이유이다.
다음 포스팅에서는 분석작업시 자주 사용되는 Polars 함수를 설명하겠다.'학습 > Python' 카테고리의 다른 글
FFT를 활용한 시계열 데이터 노이즈 처리 in Python (1) 2023.10.27 Warning 없이 Pandas Dataframe의 데이터 조작하기 - replace (0) 2023.01.12